The Bio-ASP Lab
In CITI, Academia Sinica was founded in November, 2011. We are dedicated to developing novel
acoustic signal processing and artificial intelligence algorithms and apply them to
biomedical and biology related tasks.
The main research focuses include five parts:
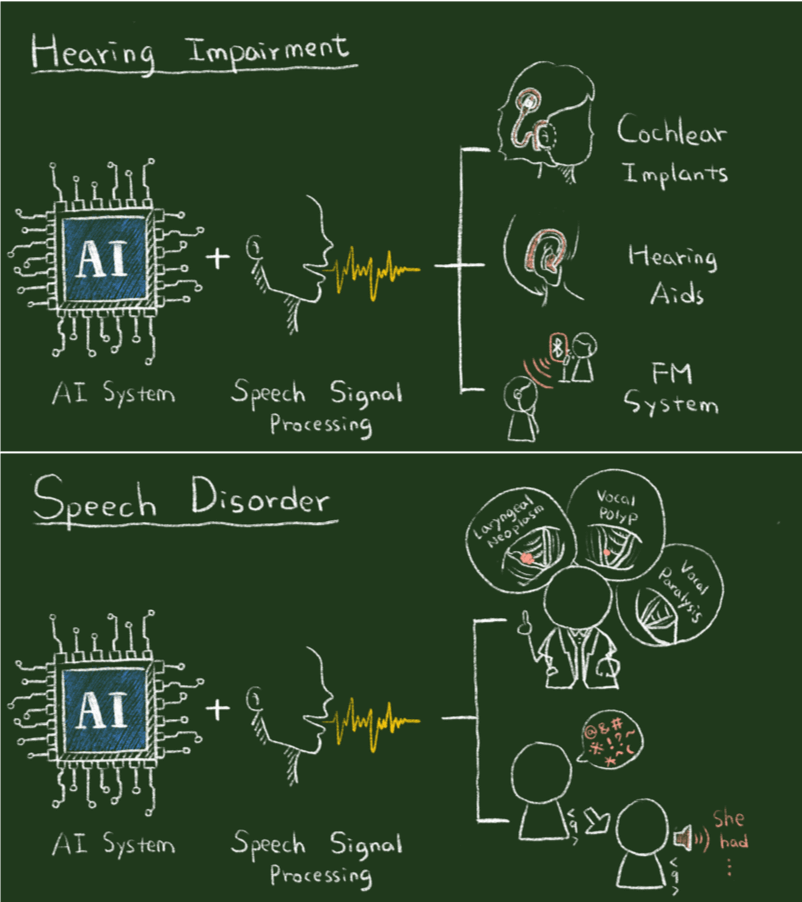
![]() AI for assistive speech communication
technologies
AI for assistive speech communication
technologies
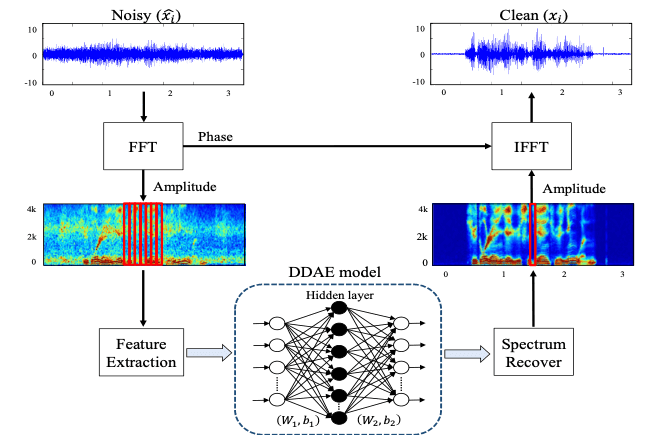
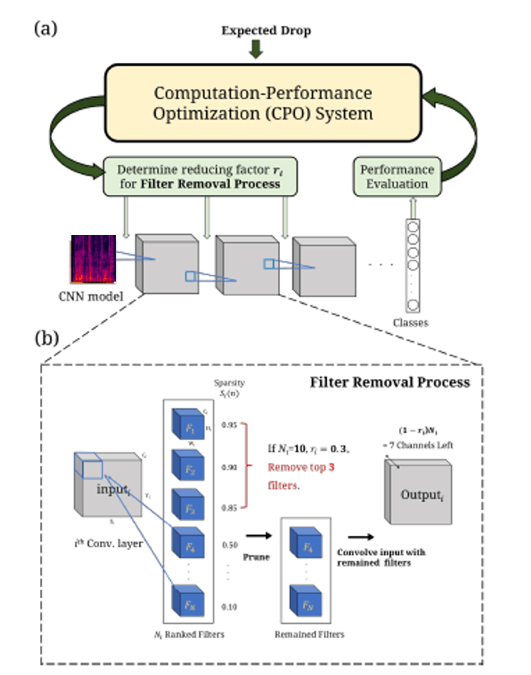
![]() Deep learning based speech signal processing
Deep learning based speech signal processing
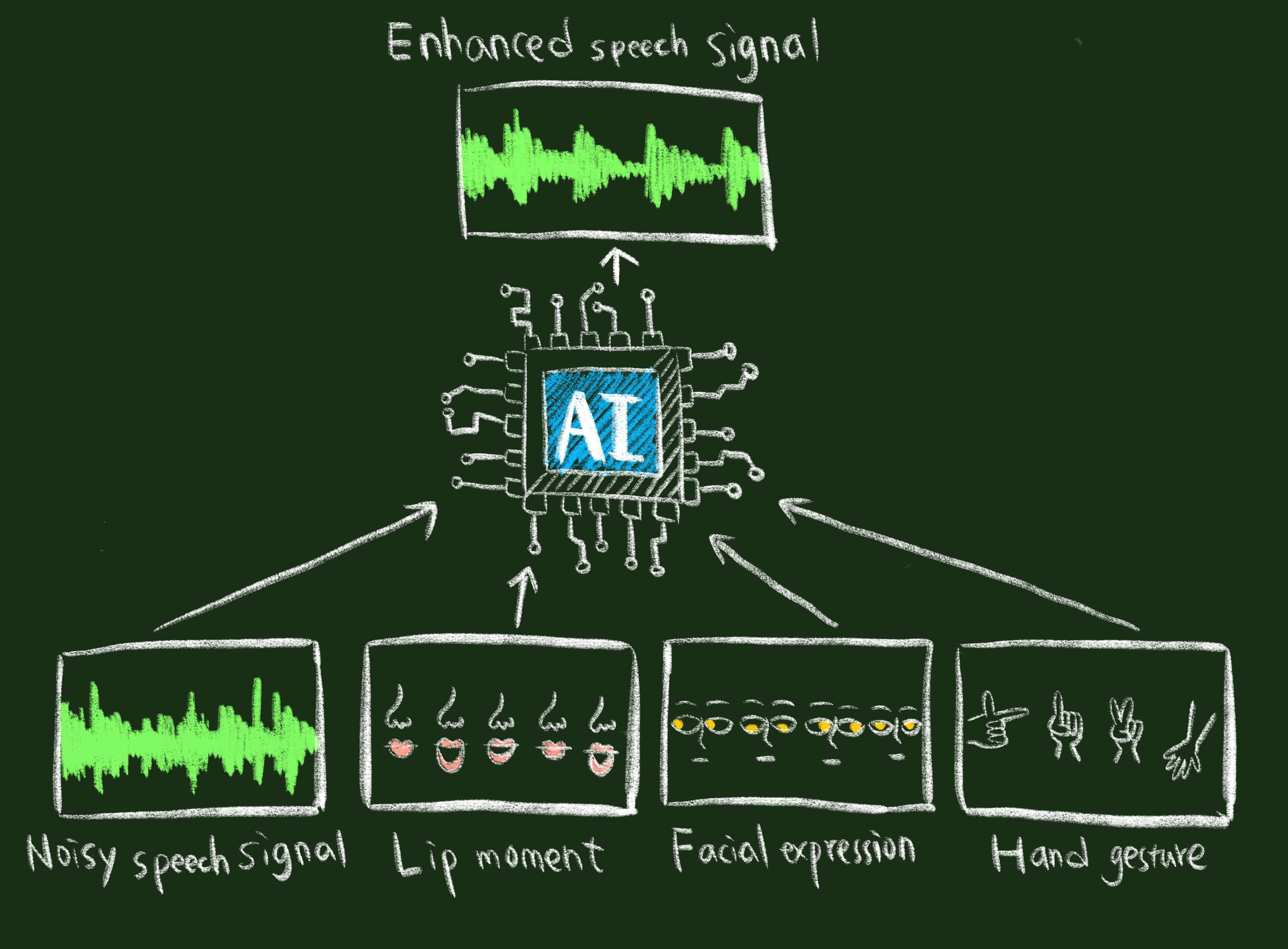
![]() Multi-modal speech signal processing
Multi-modal speech signal processing
![]() Soundscape information retrieval
Soundscape information retrieval
So far, the Bio-ASP Lab has published more than 52 journal papers and 120 international conference papers. Among them, the Bio-ASP Lab received Best Poster Presentation Award in IEEE MIT URTC 2017, Poster Presentation Award in APSIPA 2017, Best Paper Award in ROCLING 2017, Excellent Paper Award in TAAI 2012. Meanwhile, an Interspeech 2014 paper received the best paper award nomination, four papers have received the ISCA travel grant awards, and one paper received the ICML travel grant. A co-advised PhD student received the PhD Thesis Award by ACLCLP in 2018. The Bio-ASP Lab also received the Career Development Award, Academia Sinica in 2017, and National Innovation Award in 2018.